2020. 8. 3. 17:24ㆍML in Python/Python
*아래 학습은 Fastcampus의 "머신러닝 A-Z까지"라는 인터넷 강의에서 실습한 내용을 복습하며 학습과정을 공유하고자 복기한 내용입니다.
이 게시글은 오로지 파이썬을 통한 실습만을 진행한다. 중요변수를 추출하기 위한 방법과 shap value의 개념 및 원리를 알고자하면 아래 링크를 통해학습을 진행하면 된다.
https://todayisbetterthanyesterday.tistory.com/56
[Data Analysis 개념] Ensemble(앙상블)-4 : Feature Importance & Shap Value
1. Feature importance 앙상블에서 변수 해석의 문제 앙상블 모형은 많은 모델들이 기본적으로 Tree 기반으로 이루어진다. 동시에, 이 Tree기반의 앙상블들은 전반적으로 우수한 성능을 내는 모델들이�
todayisbetterthanyesterday.tistory.com
실습에 사용할 데이터는 아래의 데이터이다. 집 price가 target이고 그 외 집의 특성을 뜻하는 변수들이 feature로 존재한다. 상세한 내용은 아래와 같다.
id: 집 고유아이디
date: 집이 팔린 날짜
price: 집 가격 (타겟변수)
bedrooms: 주택 당 침실 개수
bathrooms: 주택 당 화장실 개수
floors: 전체 층 개수
waterfront: 해변이 보이는지 (0, 1)
condition: 집 청소상태 (1~5)
grade: King County grading system 으로 인한 평점 (1~13)
yr_built: 집이 지어진 년도
yr_renovated: 집이 리모델링 된 년도
zipcode: 우편번호
lat: 위도
long: 경도
이제 shap value를 시각화시켜 구현하는 과정을 진행해보자.
1. 데이터 준비
# library import
import os
import pandas as pd
import numpy as np
from sklearn.model_selection import train_test_split# 현재경로 확인
os.getcwd()
# 데이터 불러오기
data = pd.read_csv("./kc_house_data.csv")
data.head() # 데이터 확인
# shape 파악
nCar = data.shape[0] # 데이터 개수
nVar = data.shape[1] # 변수 개수
print('nCar: %d' % nCar, 'nVar: %d' % nVar )# 의미가 없다고 생각되는 변수 제거
data = data.drop(['id', 'date', 'zipcode', 'lat', 'long'], axis = 1) # id, date, zipcode, lat, long 제거feature_columns = list(data.columns.difference(['price'])) # price-target, 그 외 feature
X = data[feature_columns]
y = data['price']
train_x, test_x, train_y, test_y = train_test_split(X, y, test_size = 0.3, random_state = 42)
# train/test 비율을 7:3
print(train_x.shape, test_x.shape, train_y.shape, test_y.shape) # 데이터 확인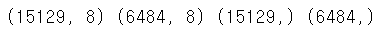
위의 경우까지는 sklearn을 활용한 실습을 했을 때, 반복했던 과정이기에 설명을 생략하겠다.
2. Shap Value 실습을 위한 LightGBM 모델 구현
# lightgbm을 구현하여 shap value를 예측할 것
# ligthgbm 구현
# library
import lightgbm as lgb # 없을 경우 cmd/anaconda prompt에서 install
from math import sqrt
from sklearn.metrics import mean_squared_error
# lightgbm model
lgb_dtrain = lgb.Dataset(data = train_x, label = train_y) # LightGBM 모델에 맞게 변환
lgb_param = {'max_depth': 10,
'learning_rate': 0.01, # Step Size
'n_estimators': 1000, # Number of trees
'objective': 'regression'} # 목적 함수 (L2 Loss)
lgb_model = lgb.train(params = lgb_param, train_set = lgb_dtrain) # 학습 진행
lgb_model_predict = lgb_model.predict(test_x) # test data 예측
print("RMSE: {}".format(sqrt(mean_squared_error(lgb_model_predict, test_y)))) # RMSE
이는 lightGBM모델로 boosting(Gradient Boosting)의 방법 중 하나이다. 즉, Decision Tree 기반의 Ensemble모형을 구현한 것이다. 이 모델의 RMSE 결과는 212217로 나왔다. 이 모델을 해석하기 위한 Shap Value를 구현해보자.
3. Shap Value 구현 & 시각화
# shap value를 이용하여 각 변수의 영향도 파악
# !pip install shap (에러 발생시, skimage version 확인 (0.14.2 이상 권장))
# import skimage -> skimage.__version__ (skimage version 확인)
# skimage version upgrade -> !pip install --upgrade scikit-image
# shap value
import shap
explainer = shap.TreeExplainer(lgb_model) # Tree model Shap Value 확인 객체 지정
shap_values = explainer.shap_values(test_x) # Shap Values 계산# version 확인
import skimage
skimage.__version__
Shap Value는 기본적으로 cmd에서 "pip install shap"를 통해 설치를 해야한다. 그리고 sklearn image package 또한 사용할 것이기에 동일한 방법으로 설치를 하여야 한다.
Shap value를 통해 Tree기반의 Explainer를 생성할 것이고 해당 함수에 인수로 미리 만들어 두었던 lightGBM모델을 입력하였다. explainer를 만들어주어 .shap_values()함수를 통해서 shap value의 계산과정을 진행한다.
shap.initjs() # javascript 초기화 (graph 초기화)
shap.force_plot(explainer.expected_value, shap_values[1,:], test_x.iloc[1,:])

위의 과정은 첫 번째 test data instance에 대해 Shap Value를 적용하여 시각화한 것이다. 빨간색이 영향도가 높은 것이고, 파란색이 영향도가 낮은 것이다. 즉 집의 condition과 bedrooms/bathrooms가 집 가격에 큰 양의 영향력을 주고, yr_bulit, floors, waterfront는 음의 영향력을 준다고 보여진다.
# 전체 검증 데이터 셋에 대해서 적용
shap.force_plot(explainer.expected_value, shap_values, test_x) 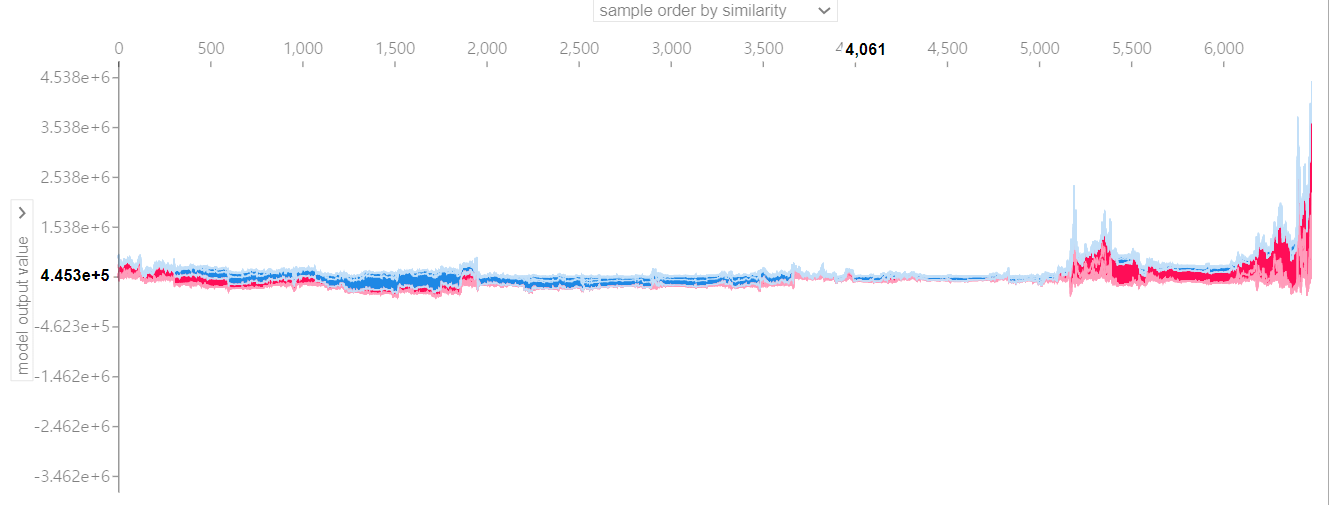
이는 전체 test데이터 셋에 대해서 적용한 것이다. 가로축에는 변수와 sample order를 선택할 수 있는 피벗이 생성되고, 세로축에는 각각의 변수에 대한 영향력과 model output value를 선택할 수 있는 피벗이 생성된다. 이를 바꿔가면서 변수에 대한 영향력과 전반적인 모델의 설명을 확인할 수 있다.
# summary
shap.summary_plot(shap_values, test_x)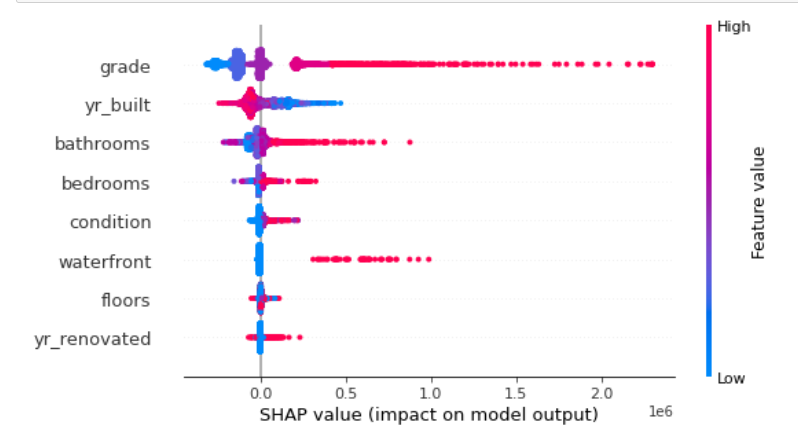
위는 모든 변수들의 shap value를 요약한 것이다. 해당 변수가 빨간색을 띄면 target(price)에 대해 양의 영향력이 존재하는 것이고, 파란색을 띄면 음의 영향력이 존재하는 것이다. 해석을 하면 아래와 같다.
- grade : 변수의 값이 높을 수록, 예상 가격이 높은 경향성이 있다.
- yr_built : 변수의 값이 낮을 수록, 예상 가격이 높은 경향성이 있다.
- bathrooms : 변수의 값이 높을 수록, 예상 가격이 높은 경향성이 있다.
- bedrooms : 변수의 값이 높을 수록, 예상 가격이 높은 경향성이 있다.
- condition : 변수의 값이 높을 수록, 예상 가격이 높은 경향성이 있다
- waterfront : 변수의 값이 높을 수록, 예상 가격이 높은 경향성이 있다.
- floors : 해석 모호성 (Feature Value에 따른 Shap Values의 상관성 파악 모호)
- yr_renovated : 해석 모호성 (Feature Value에 따른 Shap Values의 상관성 파악 모호)
# 각 변수에 대한 |Shap Values|을 통해 변수 importance 파악
shap.summary_plot(shap_values, test_x, plot_type = "bar")
이는 각 변수의 shap value에 절대값을 취한 것으로 변수의 평균적인 영향력을 보여준다. 큰 영향력을 보일 수록, target과 관계성(인과관계X)이 크다는 것이다. 즉, 변수의 중요도와 비슷한 개념이다.
# 변수 간의 shap value 파악
shap.dependence_plot("yr_built", shap_values, test_x)
이는 변수간 의존성을 보여주는 shap value이다. 위를 보면, 빨간 점이 최신일수록 파란점에 비해 많이 분포하기에, 최신 집일수록 grade가 높은 경향이 있다고 보여진다.
shap value는 이러한 방식으로 구현할 수 있다. 더 많은 자세한 내용이 있지만 추가적인 내용은 아래 링크의 shap github를 통해서 확인하길 바란다.
slundberg/shap
A game theoretic approach to explain the output of any machine learning model. - slundberg/shap
github.com
'ML in Python > Python' 카테고리의 다른 글
| [Python] Hierarchical clustering(계층적 군집분석) (0) | 2020.08.09 |
|---|---|
| [Python] K-means clustering (0) | 2020.08.09 |
| [Python] Ensemble(앙상블) - Boosting(AdaBoost, Gradient Boosting) (0) | 2020.07.31 |
| [Python] Ensemble(앙상블) - Random Forest(랜덤포레스트) (0) | 2020.07.31 |
| [Python] Ensemble(앙상블) - Bagging (0) | 2020.07.31 |