2020. 7. 22. 22:57ㆍML in Python/Python
이 게시글은 오로지 파이썬을 통한 실습만을 진행한다. 인공신경망 모형의 개념 및 원리를 알고자하면 아래 링크를 통해학습을 진행하면 된다.
https://todayisbetterthanyesterday.tistory.com/42
[Data Analysis 개념] 인공신경망(Artificial Neural Network) 모형의 원리와 구성 - Perceptron / Activation function
이 게시글은 인공신경망에 대한 개념만을 다룬다. python에서 sklearn을 활용한 구현은 아래 링크를 통해 남겨놓도록 하겠다. https://todayisbetterthanyesterday.tistory.com/41 [Python] sklearn을 활용한 인..
todayisbetterthanyesterday.tistory.com
1. Artificial Neural Network 요약
이번 게시글에서는 인공신경망(Artificial Neural Network)에 대한 개념을 다루지 않고 scikit learn라이브러리를 활용하여 Neural Network 모형을 구축해보는 실습을 진행할 것이다.
인공 신경망 모형은 인간의 뉴런을 모방하여 알고리즘으로 구현할 것을 말한다. 인간의 뉴런은 시냅스를 통하여 다른 여러 뉴런으로 부터 자극을 전달받고 이를 또다른 뉴런으로 전달시키는 과정을 거친다.
이 인간의 뉴런을 "퍼셉트론"이라는 인공 뉴런을 구성하고 이 퍼셉트론들이 여러 layer를 거치며 시냅스를 통한 자극의 전달과정을 모방한 것이 Neural Network이다.
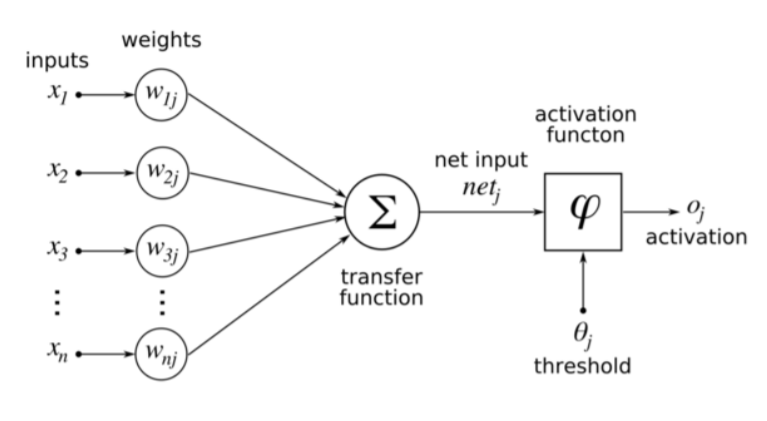
Neural Network에서는 가장 중요한 구성요소로 inputs / weights / activation function / error(bias) 를 꼽을 수 있다. Neural Network의 과정을 간략하게 말하자면, input layer에서 inputs값들이 여러개의 퍼셉트론으로 이루어진 다층 퍼셉트론 layer(이를 은닉층/Hidden Layer라고 한다)를 거치며 Weigths와 error를 활성화함수를 통해 조정하면서 학습을 진행해 Output layer로 결과를 출력하는 과정이다.
이때, activation function(활성화 함수)는 sigmoid function / ReLU / leaky ReLU / ELU 등 여러가지 존재하지만,
1. gradient vanishing 문제
2. 중간에 Global minimum을 찾지 못하고, local minimum에서 학습을 멈추는 문제
와 같은 이유로 ReLU관련 활성화 함수를 요즘은 많이 쓴다.
그 외 backpropagation 등 기본적인 원리에 많은 것들에 대한 설명이 필요하지만 자세한 수학적 원리와 과정은 다음 게시물을 통해서 다루겠다. Python에서 sklearn이라는 module을 통해서 실습을 진행해보자. 물론 keras와 tensorflow를 통해서 또한 진행할 수 있으나, sklearn은 머신러닝에 대해서 처음 접하는 사람이 쓰기 매우 편한 점이 모든 학습 모델과 적합 함수의 형태가 동일하다는 것이다. 여튼 이제 진행해보겠다.
2. Python sklearn을 통한 Neural Network 구현
1) 기본적인 sklearn의 Neural Network 형태
# 1.간단한 데이터셋 생성
X = [[0., 0.], [1., 1.]]
y = [[0, 1],[1, 1]]
# 2.neural network 함수 불러오기
from sklearn.neural_network import MLPClassifier
# 3.neural network 모델 적합
clf = MLPClassifier(solver = "lbfgs", alpha = 1e-5, hidden_layer_sizes = (5,2), random_state = 1)
clf.fit(X,y)모델적합에서 solver를 "lbfgs"로 설정한 것은 해를 구하는 방법의 알고리즘을 정해준 것이다. alpha값은 학습에 대한 제약의 정도를 뜻하는데 작은 수치를 줄 수록 제약이 없다는 것이고, 큰 수치를 줄 수록 과적합 방지를 위해 과한 학습에 대한 제약을 행한다는 뜻이다.
hidden_layer_size = (5,2)로 2개의 은닉층을 생성하는데 첫 번째 hidden layer의 노드(퍼셉트론) 수는 5개, 두 번째 hidden layer의 노드 수는 2개를 생성한다고 설정한 것이다. random_state는 실습결과의 동일성을 위해 난수를 고정시킨 것이다.
# 4. 예측
clf.predict([[2.,2.],[-1.,-2]])

예측 결과를 나타내는 함수이다. 다른 sklearn model의 함수와 동일하다. 위의 결과는 별 의미가 없지만 분류 기준을 추측해 보자면, [1,1] 보다 작은 경우는 [0,1]로 분류하고, [1,1]보다 크거나 작은 경우는 [0,1]로 분류하는 것으로 추측해 볼 수 있다.
# 5. weights 확인
clf.coefs_

위의 coefs_ 함수는 Neural Network에 속하는 hidden layer에 적용되는 weight를 의미하는 것이다. weight에 대한 구조는 아래와 같다.
input 2개 -> 첫 번째 은닉층의 5개 퍼셉트론(노드)
첫 번째 은닉층의 5개 노드 -> 두 번째 은닉층의 2개 노드
두 번째 은닉층의 2개 노드 -> output 2개
의 구조에 해당하는 weight인 것이다.
# 5. layer shape 확인
[coef.shape for coef in clf.coefs_]

위는 layer의 형태인 것이다. 쉽게 표현하자면 아래와 같다.
(inputs) 2 -> 5 (first hidden layer) 5->2 (second hidden layer) 2-> 2 (outputs)
가장 기본적인 형태의 sklearn을 활용한 Neural Network를 알아보았다. 이제 좀 더 복잡한 데이터와 모델을 통해 실습을 진행해보자.
1) model의 복잡도에 따른 퍼포먼스 비교
## 1. module import
# 데이터셋과 시각화용 라이브러리
import numpy as np
import pandas as pd
from matplotlib import pyplot as plt
from matplotlib.colors import ListedColormap
from sklearn.datasets import make_moons, make_circles, make_classification
# 데이터 분류와 모델 형성에 사용되는 라이브러리
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.neural_network import MLPClassifier
## 2. parameter 설정
h = .02 # visualization을 위한 parameter / not for NN
alphas = np.logspace(-5,3,5) # NN의 alpha값
names = ['alpha' + str(i) for i in alphas] # 시각화시 plot의 title용
위의 alphas와 names 변수의 출력결과는 아래와 같다.
alphas - array([1.e-05, 1.e-03, 1.e-01, 1.e+01, 1.e+03]) - 이는 모델의 과적합을 방지하기 위한 제약을 거는 것이다. 작은 수일 수록 제약이 없는 것이고, 높은 수일 수록 제약이 늘어나 과적합을 방지하는 것이다.
names - ['alpha 1e-05', 'alpha 0.001', 'alpha 0.1', 'alpha 10.0', 'alpha 1000.0']
## 3. alpha값에 따른 Neural Network model 생성
classifiers = []
for i alphas :
classifiers.append(MLPClassifier(solver = 'lbfgs',alpha = i, random_states = 1,
hidden_layer_sizes = [100,100]))alpha값이 각기 다른 모델을 새로 만들었다. 이제 데이터를 생성해서 실습을 진행해보자.
## 4. 데이터 생성
X, y = make_classification(n_features = 2, n_redundant = 0, n_informative = 2
, random_state = 0, n_clusters_per_class = 1) # 4-1. x data 확인
pd.DataFrame(X).head()
# 4-2. y data 확인
pd.DataFrame(y).head()

# 4-3. uniform error 생성
rng = np.random.RandomState(2)
X += 2*rng.uniform(size = X.shape)
linearly_separable = (X,y)# 4-4. 여러 모양(달/원형/선형)의 추가 데이터셋 생성
datasets = [make_moons(noise = 0.3, random_state = 0),
make_circles(noise = 0.2, factor = 0.5, random_state = 1),
linearly_separable]
# 4-5 figure 생성
figure = plt.figure(figsize = (18,6))
여기까지 데이터셋을 생성해보았다. 각각 달모양/원형/선형으로 구획이 나눠지는 데이터셋이다. 이를 각 alpha값마다 학습을 시키고 시각화작업을 진행해보자.
## 5. 3개의 데이터 구조를 5개의 alpha값에 따른 학습과 시각화 작업
# 데이터셋 3종류, moon,circle,linear data - 반복
for X,y in datasets :
X = StandardScaler().fit_transform(X)
X_train, X_test, y_train, y_test = train_test_split(X,y, test_size = 4)
# grid 생성
x_min, x_max = X[:, 0].min() - 5, X[:,0].max() +5
y_min, y_max = X[:, 0].min() - 5, X[:,0].max() +5
xx, yy = np.meshgrid(np.arange(x_min, x_max, h),
np.arange(y_min, y_max, h))
# dataset 시각화를 위한 plot작업
cm = plt.cm.RdBu
cm_bright = ListedColormap(['#FF0000','#0000FF'])
ax = plt.subplot(len(datasets), len(classifiers) + 1, i)
# training point plot
ax.scatter(X_train[:,0],X_train[:,1], c=y_train, cmap=cm_bright)
# testing point plot - 여기서 alpha값은 sklearn의 알파와 다름, 투명도를 의미
ax.scatter(X_test[:,0], X_train[:,1], c=y_train, cmap=cm_bright, alpha = 0.6)
ax.set_xlim(xx.min(), xx.max())
ax.set_ylim(yy.min(), yy.max())
ax.set_xticks(())
ax.set_yticks(())
i += 1
# classifiers iterate - alpha값에 따른 5개의 분류기준 반복
for name, clf in zip(names, classifiers):
ax = plt.subplot(len(datasets), len(classifiers) + 1, i)
clf.fit(X_train, y_train)
score = clf.score(X_test, y_test)
# plot의 초평면(Decision Boundary)를 기준으로 다른 색을 할당
if hasattr(clf, "decision_function"):
Z = clf.decision_function(np.c_[xx.ravel(), yy.ravel()])
else:
Z = clf.predict_proba(np.c_[xx.ravel(), yy.ravel()])[:, 1]
# Put the result into a color plot
Z = Z.reshape(xx.shape)
ax.contourf(xx, yy, Z, cmap=cm, alpha=.8)
# Plot also the training points
ax.scatter(X_train[:, 0], X_train[:, 1], c=y_train, cmap=cm_bright,
edgecolors='black', s=25)
# and testing points
ax.scatter(X_test[:, 0], X_test[:, 1], c=y_test, cmap=cm_bright,
alpha=0.6, edgecolors='black', s=25)
ax.set_xlim(xx.min(), xx.max())
ax.set_ylim(yy.min(), yy.max())
ax.set_xticks(())
ax.set_yticks(())
ax.set_title(name)
ax.text(xx.max() - .3, yy.min() + .3, ('%.2f' % score).lstrip('0'),
size=15, horizontalalignment='right')
i += 1
figure.subplots_adjust(left=.02, right=.98)
plt.show()
위의 plot이 선명하게 나오지가 않았다. 개인적인 컴퓨터의 문제인듯하다.(같은 코드를 사용했지만, 다르게 출력됨) 위의 경우를 보면 맨 위부터 1.moon / 2. circles / 3.linear 형태로 구분된 데이터셋에 대한 학습결과의 colormap이다.
맨 왼쪽 열은 원본 데이터의 산점도 그리고 오른쪽으로 갈 수록 alpha값이 커지는 결과이다.(overfitting 방지를 위한 학습에 제한을 거는 것) 위에서 보면 2열의 데이터가 가장 분류를 잘 시킨다. 물론 Overfitting되었을 가능성이 크다. (학습데이터로 시각화를 진행했기때문) 그리고, 맨 오른쪽의 데이터들은 분류를 전혀하지 못했다. alpha =1000이라는 수치가 너무 큰 수치이기 때문이다.
사실 Neural Network에는 parameter가 alpha말고 더 많은 것들이 존재하지만, 다 다루기에는 너무 많아서 학습용 과정을 위해 여기까지만 진행했다. 그리고 Neural Network는 변형되고 발전되어 다른 알고리즘들로 잘 진행했기에 기본의 과정이지, 실제 모델에 적합하기에는 한정적이기도 하다. 물론 기본이기에 어느 NN과도 밀접한 관련이 있어서 학습할 필요는 있다.
다음 실습으로는 앙상블 모형들에 대해서 진행하도록 하겠다.
'ML in Python > Python' 카테고리의 다른 글
| [Python] Ensemble(앙상블) - Random Forest(랜덤포레스트) (0) | 2020.07.31 |
|---|---|
| [Python] Ensemble(앙상블) - Bagging (0) | 2020.07.31 |
| [Python] 의사결정나무(DecisionTree) 구현 - 분류(Classifier)/회귀(Regressor)/가지치기(Pruning) (4) | 2020.07.18 |
| [Python] SVM(Support Vector Machine)구현 실습 (1) | 2020.07.16 |
| [Python] LDA(Linear Discriminant Analysis - 선형판별분석)/QDA(Quadratic Discriminant Analysis - 이차판별분석) 구현 실습 (0) | 2020.07.08 |