2020. 7. 3. 18:57ㆍML in Python/Knowledge
머신러닝을 실행시키다 보면 크게 나타나는 문제 중
1. 과적합 문제 해결
2. Sample loss 문제 해결
을 위해서 존재하는 검증법이 바로 Cross Validation(교차검증법)이다.
먼저, Sample Loss 문제는 Train-(Validation)-Test 으로 데이터 셋을 나눌 때, 데이터를 나누면서 학습데이터가 적어지는 데이터 소실 문제가 발생한다.
그렇다고 온전히 갖고 있는 데이터셋을 모두 Train Set으로 돌리고 학습을 시키자니, Train(학습)데이터에만 성능이 좋은 Overfitting(과적합)이 발생한다.
이러한 상황속에서, 학습이 발생시키는 Error를 과소추정하지 않으면서 데이터의 소실을 최소화하는 방법이 바로 Cross Validation(교차검증법)이다.
k-Fold Cross Validation
아래는 K=5인 k-Fold Cross Validation의 예시이다.

위의 그래프를 보자면 Fold가 5로 이루어져 있다. 즉 한가지 데이터 셋을 5분의 1로 나누어, 각 Fold마다 한 번씩 Test데이터로 사용되도록 하여 총 5번의 학습을 진행시키는 것이다. 그리고 그 학습결과로 Cross-Validation Error를 발생시킨다.
Cross-validation error
Cross validation error를 수식으로 표현하면 아래와 같다.
1.
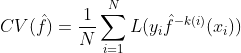
여기서
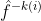
는 i번째 Fold 관측치를 제외하고 fitting한 모델이다.
2.
즉, 이 식의 의미는 i번째 Fold를 제외한 학습 오차( L = loss function, 예시 - MSE )의 Loss들을 모두 더해, K(=N)으로 나누어 평균을 내준 것이다.
이상 K-Ford Cross Validation에 대한 짧은 설명이었다. 이를 KNN과 함께 Python으로 구현하는 게시글을 다음 시간에 작성하도록 하겠다.
'ML in Python > Knowledge' 카테고리의 다른 글
| [Data Analysis 개념] LDA와 QDA의 이해 (1) | 2020.07.09 |
|---|---|
| [Data Analysis 개념] 차원 축소법 - PCA(주성분 분석) (0) | 2020.07.07 |
| [Data Analysis 개념] KNN(K-Nearest-Neighbors)알고리즘 (0) | 2020.07.03 |
| [Data Analysis 개념] NaiveBayes(나이브 베이즈) 모델 - 조건부 확률 / 베이즈 정리 / Multinomial, Gaussian, Bernoulli NaiveBayes (0) | 2020.07.02 |
| [Data Analysis 개념] 차원의 저주 (0) | 2020.06.25 |