2020. 7. 14. 15:02ㆍADP | ADsP with R/Knowledge
R언어와 사용법에 관한 게시글들은 "한국 데이터 산업진흥원"에서 출간한 국가공인 ADP/ADsP자격증을 위한 "데이터 분석 전문 가이드"에 서술된 수준에 한정지어 다루어 볼 것입니다.
ADP필기 준비를 위한 R의 기본적인 문법과 패키지들을 학습을 목표로 합니다.
1. 데이터 마트의 정의
데이터 마트란 데이터의 한 부분으로 특정 사용자가 관심을 갖는 데이터들을 담은 비교적 작은 규모의 데이터 웨어하우스이다.
즉, 일반적인 데이터베이스 형태로 갖고 있는 다양한 정보를 사용자의 요구 항목에 따라 체계적으로 분석하여 기업의 경영활동을 돕기 위한 시스템을 말한다.
데이터 웨어하우스는 정부 기관 또는 정부 전체의 상세 데이터를 포함하는 반면, 데이터 마트는 전체적인 데이터 웨어하우스에서 일부 데이터를 가지고 특정 사용자를 대상으로 한다.
다시 말하면, 데이터 웨어하우스와 데이터 마트의 구분은 사용자의 기능 및 제공 범위를 기준으로 한다.
2. sqldf을 활용하여 데이터 마트 개발하기
데이터는 여러 계층으로 그룹화/계층화를 시키거나 또는 다양한 관점을 통해 분석할 필요가 있다. 데이터 분석을 하기 이전에 데이터 재정렬을 하거나 밀집화(aggregation)을 진행할 수 있는데 밀집화는 우리가 잘 아는 엑셀의 피벗테이블과 같은 형태이다.
밀접화는 직관적인 이해를 시킬 수 있지만, 데이터에 있어서 많은 정보의 손실을 야기한다. 그렇기에 재정렬을 통해 데이터의 모든 정보를 유지하고 데이터를 다양한 각도에서 보는 해석을 할 역량을 기를 필요가 있다.
지금부터, R에서 sqldf패키지를 통해 실습을 진행하고자 한다. sqldf패키지는 sql 쿼리를 이용해 데이터를 재구성하거나 밀집화된 데이터를 유연하게 생성해준다. 이를 직접 실습해보자.
1) sqldf 패키지 설치 및 로드
install.packages("sqldf") # 패키지 설치, 사용전 최초 1회
library(sqldf) # sqldf를 새로운 R script에서 쓸때마다 새로 불러와야함.2) sqldf를 활용한 데이터 가져오기
data(iris)
sqldf("select * from iris")
select * from iris - iris에서 모든 데이터를 다 불러오는 것이다. 150개 행의 데이터가 출력되었지만 업로드의 편의를 위해 일부 결과만 가져왔다.
sqldf("select * from iris limit 10")
select * from iris limit 10 - iris에서 상위 10개 데이터를 가져오는 것이다.
sqldf("select * from iris where Species like 'se%'")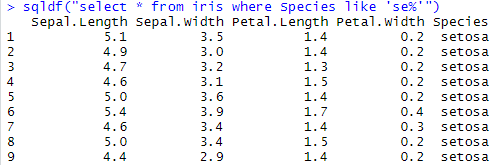
select * from iris where Species like 'se%' - iris에서 species가 se로 시작하는 것들을 가져오는 것이다.
※sqldf 패키지는 보다시피 sql문을 활용하여 데이터의 부분을 가져오고 출력해 사용하는 것이다. 사실 이 패키지를 활용하기 위해서는 무엇보다 sql구문에 대한 이해가 필요하다. 이는 R과 별도로 학습할 필요가 있다.
3. plyr을 활용하여 데이터 마트 개발하기
plyr은 데이터를 분리하고 처리하고, 다시 결합하는 등의 작업을 위한 가장 필수적인 데이터 처리기능을 제공한다. apply함수와 multi-core함수를 이용하여 반복문 작업없이 빠른 데이터의 처리가 가능하다. 기본적으로 apply함수에 기반해 데이터와 출력변수를 배열로 치환하여 처리하는 패키지이다.
ply()함수는 앞의 두개의 문자 접두사를 가지는 데 00ply()형식으로 이루어진다. 첫 번째 0에 입력 데이터 형태, 두 번째 0에 출력 데이터 형태로 이루어진다. 0에 들어갈 접두사는 아래와 같다.
1. d = 데이터프레임 (data.frame)
2. a = 배열 (array)
3. l = 리스트(list)
1) plyr 패키지 설치 및 로드
install.packages("plyr") # 패키지 설치, 사용전 최초 1회
library(plyr) # plyr를 새로운 R script에서 쓸때마다 새로 불러와야함.
2) 실습에 사용될 데이터셋 만들기
set.seed(1)
d = data.frame(year = rep(2012:2014, each =6), count = round(runif(9,0,20)))
print(d)
실습에 사용할 데이터를 만들기 위해 난수로 d라는 데이터 프레임을 만든다. 난수는 고정을 시키기위해 set.seed()함수를 통해서 난수고정을 해주고, year변수를 2012~2014까지 각각 6개씩 존재하도록 each=6을 지정해 주엇다.
count라는 변수에 난수를 생성하는 runif함수와 반올림을 통해서 난수를 생성한다. runif의 사용법은 아래와 같다.
# runif(생성할 난수 개수, 최소값 최대값) - 소수점을 사용하지 않을 경우 round를 통해서 반올림해준다.
3) plyr실습
# 입력:데이터 프레임 / 출력:데이터 프레임 - ddply
# 연별로 변동계수 구하는 함수
ddply(d, "year", function(x){
mean.count = mean(x$count)
sd.count = sd(x$count)
cv = sd.count/mean.count
data.frame(cv.count = cv)
})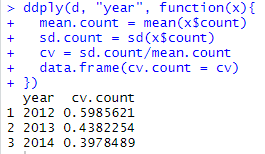
ddply내 삽입할 함수(function(x))를 구문 내에서 생성하여 바로 적용하였다. 함수를 직접 가져다 쓸 수도 있다.
# 입력:데이터 프레임 / 출력:데이터 프레임 - ddply
# summarise
ddply(d, "year", summarise, mean.count = mean(count))

summarise의 경우 특정 변수에 명령된 평균 또는 합 등을 계산해주고 새로 생긴 변수만 보여준다.
# 입력:데이터 프레임 / 출력:데이터 프레임 - ddply
# transform
ddply(d, "year", transform, total.count = sum(count))
transform의 경우 특정 변수에 명령된 평균 또는 합 등을 계산해주고 기존 변수와 함께 보여준다.
※ 그 외 plyr라이브러리에서 많은 것들을 할 수 있다. d_ply를 통해 plotting을 진행할 수도 있으며, 여러 변수를 활용하여 reshape처럼 데이터를 나눌 수도 있다. plyr 패키지 설명서를 통해 더 자세한 사항들을 확인할 수 있다.
4. data.table을 활용하여 데이터 마트 개발하기
데이터 테이블은 데이터 프레임과 유사하지만 빠른 그룹화와 순서화(orderizationP이 가능하고 짧은 문장을 통해 쉽게 활용할 수 있다. 하지만 항상 빠른 것이 아니므로 특성에 맞게 사용해야할 필요가 있다. 특히 대용량 RAM이 장착되어있는 환경일 경우 효율적이다.
1) data.table 패키지 설치 및 로드
install.packages("data.table") # 패키지 설치, 사용전 최초 1회
library(data.table) # plyr를 새로운 R script에서 쓸때마다 새로 불러와야함.
2) data.table 실습 (data.frame과 비교)
# data.table() 함수를 활용하여 데이터 프레임 생성
DT = data.table(x = c("b","b","b","a","a"), v=rnorm(5))
DT
데이터 테이블도 데이터 프레임과 같은 방법으로 생성된다. 데이터 테이블은 데이터 프레임과 달리 행번호가 :을 포함하고 있어 쉽게 알아볼 수 있다. 그리고 위에 rnorm(5)는 변수v에 랜덤 정규분포 5개의 난수를 생성해준 것이다.
# 실습에 사용될 데이터셋(데이터 프레임) 불러오기
data(cars)
head(cars)

# 데이터셋을 데이터 테이블 형식으로 변환
CARS <- data.table(cars)
head(CARS)
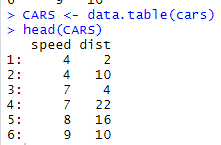
데이터 테이블과 데이터 프레임의 다른점 : 이 확연하게 보인다.
# 데이터 테이블의 정보확인
tables() # 모든 data.table의 용량/키/행개수/열개수/컬럼 정보를 알려줌
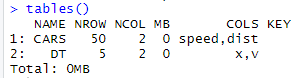
# 데이터 테이블 컬럼 정보확인
sapply(CARS, class) # 각 컬럼들의 데이터 형태를 알려줌
# 데이터 테이블에서 특정 값 찾기
DT # 전체 데이터를 출력
DT[2,] # 2행의 데이터를 출력
DT[DT$x=="b",] # x값이 "b"인 데이터를 출력
# 데이터 테이블에 key를 지정하기
tables() # key 지정 전
setkey(DT,x) # key 지정
tables() # key 지정 후
차이가 보이는가? 전/후에 따라 key의 표시가 아무것도 없는 것에서 x로 바뀌었다. 그리고 key값을 기준으로 자동순서화(ordering)이 된다.
DT["b",] # DT["B"], DT[DT$x=="b"]와 같은 결과
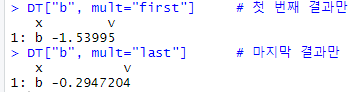
DT["b", mult="first"] # 첫 번째 결과만
DT["b", mult="last"] # 마지막 결과만
여기까지는 데이터프레임과 크게 다른 것이 없다. 다음 1000만 건 자료의 데이터 프레임을 만들어보자. 그리고 생성과 데이터 찾는 부분에 있어서 속도를 확인해보자.
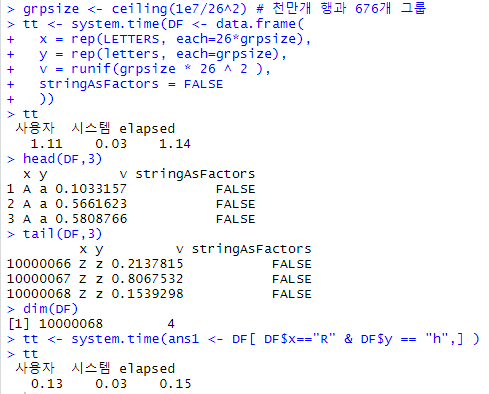
grpsize <- ceiling(1e7/26^2) # 천만개 행과 676개 그룹
tt <- system.time(DF <- data.frame(
x = rep(LETTERS, each=26*grpsize),
y = rep(letters, each=grpsize),
v = runif(grpsize * 26 ^ 2 ),
stringAsFactors = FALSE
))
tt # 생성하는데 1.14초
head(DF,3)
tail(DF,3)
dim(DF)
tt <- system.time(ans1 <- DF[ DF$x=="R" & DF$y == "h",] )
tt # 찾는데 0.15초
데이터 프레임은 위와같은 모든 자료를 비교해 찾는 벡터방식이라 데이터가 커지면 커질수록 효율성이 떨어진다. 지금은 0.1~2초 사이의 적은 시간이 걸리는 것처럼 보이지만 데이터 테이블 방식의 시간대를 확인해볼 필요가 있다.
DT <- data.table(DF)
setkey(DT,x,y)
ss <- system.time(ans2<-DT[J("R","h")]) #binary search방식
head(ans2,3)
identical(ans1$v, ans2$v) #데이터 테이블에서 찾은 데이터가 데이터 테이블에서 찾은 데이터와 동일
ss #찾는데 0초

위를 보면 같은 데이터를 찾는데 0초가 걸린 것을 확인할 수 있다. 이는 벡터를 일일하 찾아내는 방식이 아니고 binary search를 활용한 방식이기에 데이터가 커질수록 시간격차는 더욱더 커진다.
그러나, 데이터 테이블을 데이터 프레임처럼 이용할 시(key를 사용하지 않고 이용할 시), 데이터 테이블은 데이터 프레임과 성능이 비슷해진다. 그렇기에 data.table을 사용할 때, key를 적극적으로 활용할 필요가 있다.
여태까지 DT[...]안의 첫 번째 인수에 대해서 알아보았다. 이제부터 두 번째 인수와 by=에 대해 알아보자.
DT[,sum(v)] # 데이터 테이블에서 sum를 하는 경우
DT[,sum(v), by = x] # x를 기준으로 sum를 하는 경우
첫 번째는 전체를 기준으로 sum을 하였고, 두 번째는 x를 기준으로 sum을 하였다. 이는 각 그룹별 sum이 적용된 것을 확인할 수 있다.
ttt <- system.time(tt <- tapply(DT$v, DT$x, sum))
ttt
sss <- system.time(ss <- DT[,sum(v),by=x])
sss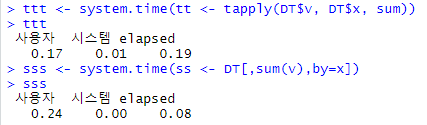
데이터 테이블에서 by는 매우 빠른 성능을 보여준다. 데이터 테이블에서 by로 작업하는 것이, tapply (table:입력 -> array:출력, ply ) 작업보다 2배 이상 빨랐다.
# 동일한 두 결과 (tapply / by)
head(tt)
head(ss)
identical(as.vector(tt),ss$V1)

당연히 두 결과는 동일하다.
# 두 변수 (x,y)를 가지고 grouping/summary 할 경우
sss <- system.time(ss<- DT[,sum(v),by = "x,y"])
sss
ss
두 변수, 혹은 그 이상의 변수를 가지고 그룹핑작업을 진행할 때는 by = "x,y"와 같이 여러 변수를 넣어주면 된다.
'ADP | ADsP with R > Knowledge' 카테고리의 다른 글
| [ADP] R을 활용한 단순회귀/다중회귀/다항회귀분석 실습 (0) | 2020.07.16 |
|---|---|
| [ADP] R - 결측값 처리와 이상값 탐색 (0) | 2020.07.14 |
| [ADP] R-데이터 마트(1) / reshape패키지(metl,cast함수) (1) | 2020.07.13 |
| [ADP] R-기초(3) : 사용자 정의 함수 / 그래픽 기능(plot) / 기타 유용한 기능 (0) | 2020.07.13 |
| [ADP] R-기초(2) : R 기초통계연산 / R 데이터 핸들링(인덱싱, 슬라이싱) / 반복문과 조건문 (0) | 2020.07.13 |