[Data Analysis 개념] Ensemble(앙상블)-4 : Feature Importance & Shap Value
1. Feature importance
앙상블에서 변수 해석의 문제
앙상블 모형은 많은 모델들이 기본적으로 Tree 기반으로 이루어진다. 동시에, 이 Tree기반의 앙상블들은 전반적으로 우수한 성능을 내는 모델들이라고도 알려져 있다.
하지만, 앙상블 기법을 사용하면서 Decision Tree들의 결합과 반복되는 학습과정에서 Decision Tree의 뛰어난 직관성이 사라진다. 변수 및 모델의 설명력을 위해서 Tree를 사용하는데 성능을 높이려고 앙상블 기법을 추가하다 보니, 원래의 목적을 잃는 것이다. 이처럼 정확성(Accuracy)과 설명력은 모델 선택에 있어서 trade-off 관계가 존재한다.
그러다 보니, 모델에 대한 해석이 필요할 때(target에 어떤 변수가 영향을 미치는지) Linear regression과 Decision Tree를 선택하고, 예측 및 분류의 성능이 중요할 때는 Ensemble과 Neural Network와 같은 복잡한 모델을 사용하게된다.
물론 Ensemble learning에서도 기본적으로 라이브러리 내 내장함수를 통해서 변수의 중요도(Importance), 즉 중요 feature를 추출할 수 있는 알고리즘을 제공한다. 그 형태는 아래의 그림과 같다.

위의 그림을 보면 Age라는 변수가 가장 중요하다는 것을 볼 수 있다. 위의 경우는 은행 이용 고객 데이터에 대해서 수입이 높은 사람을 예측하는 data이다. 우리는 직관적으로 "나이가 많으면 많을 수록 돈을 많이 벌 것이다"라는 가정 하에서 Age변수는 positive 영향력을 크게 가진다고 판단한다. 하지만, 실제로 영향력의 방향성은 제공하지 않는다. 실제로 Age라는 중요한 변수가 positive 영향력을 가질지, negative 영향력을 가질지 모른다는 것이다. 이는 데이터 분석을 진행할 때, domain knowledge가 없을 경우를 생각해보면, 함부로 판단을 내릴 수 없는 결과를 가져온다. 그리고, 데이터가 말하고자 하는 것이 통상적인 상식과 다를 경우에도 문제가 발생한다.
Feature importance
위에서 짧게나마 보았던 중요도를 측정하는 기준은 Xgboost에서는 Weight, Cover, Gain을 기준으로 판단된다. 이 기준에 대한 뜻은 아래와 같다.
Weight : 변수 별 데이터를 분리하는데 쓰인 횟수
Cover : 해당 변수로 분리된 데이터의 수
Gain : Feature을 사용했을 때 줄어드는 평균적인 training loss
이러한 기준을 통해서 feature의 importance가 구분되는 것이다.

문제가 한 가지 더 발생한다. 위의 기준으로 내린 각각의 중요한 변수를 봐보면, 각 Weight/Cover/Gain마다 너무 상이한 변수들을 중요하다고 말한다. 그렇기에 "그래서 뭐가 중요한 변수인가?"라는 질문에 쉽게 대답을 할 수가 없다. 게다가 처음 말했던 각각의 기준에 봤을 때도 어떤 변수가 어떤 방향으로(positive or negative)로 영향일 미치는지 판단을 할 수가 없다.
물론 아이 안 쓰이는 변수를 걸러낼 수는 있다. 그리고 이 Feature imporatance에도 좋고 나쁨의 기준은 있다. 그것은 바로 Consistency(일관성)이다. 즉 특정 feature를 중요하다고 판단하여 영향이 많이 가도록 모델을 수정하였다면, 중요도 측정 시 해당 feature의 중요도는 줄어들지 않아야 한다는 것이다. 쉽게 말해서, 한 앙상블 모델에 쓰인 변수가 중요하다고 판단이 되었다면, 다른 앙상블 모델을 쓰더라도 중요해야 한다는 것이다. 하지만 문제는 대부분의 feature importance 지표는 inconsistency하다는 것이다.
이러한 문제들을 보완하기 위해서 나온 방법이 바로 Shap Value이다.
2. Shap Value
Shap Value의 설명

하나의 예시를 들어보자. 평균 아파트 값이 310000유로인 데이터가 존재한다고 하자.

여기서 [ 1. nearby-park / 2. cat-forbidden / 3. area-50m^2 / 4. floor-2nd ] 의 feature를 갖는 아파트 값을 300000유로로 예측하였다고 하자. 그렇다면 실제 예측값인 300000유로와 평균 예측값인 310000의 차이인 -10000유로를 설명하기 위한 것이 바로 shap value의 목적이다.
즉, Shap Value는 실제값과 예측치의 차이를 설명하는 것이다.

우리는 이제 cat-forbidden의 기여도를 알아보고 싶다고 가정하자. 우리는 nearby-Park, area-50m^2의 연합에 cat-forbidden을 추가해보면서 파악을 할 수 있다.
1) Cat-forbidden + nearby-park + area-50m^2 이 포함된 연합에 나머지 Feature들은 무작위로 선택을 하고 예측결과(Predict)가 30.5만 유로로 나왔다.
2) Cat-forbidden을 무작위로 바꾸면서, nearby-park + area-50m^2 두 변수만 고정이고, 나머지 또한 무작위 선택을 하고 예측 결과(Predict)가 32만 유로로 나왔다.
그렇다면, 위의 1)과 2)를 계산한 Cat-forbidden의 marginal contribution은 = 30.5만 - 32만 = -1.5만 유로라고 판단할 수 있다.
즉, Sampling된 다른 feature들의 값에 따라서, 'Cat-forbidden'의 marginal contribution이 달라지고 여러번 수행하며 weighted average를 도출한다. 이것이 Cat-forbidden의 Shap Value이다.
Shap Value의 특성
이러한 방식으로 도출된 Shap Value는 여러번 수행하며 반복적인 결과물의 평균이기에 Consistency가 잘 유지된다. 그리고 Shap Value는 영향에 대한 방향성 (positive or negative) 또한 말해준다. 즉, feature importance에서 단점이 보완이 되는 것이다.
다음 그림을 봐보자.
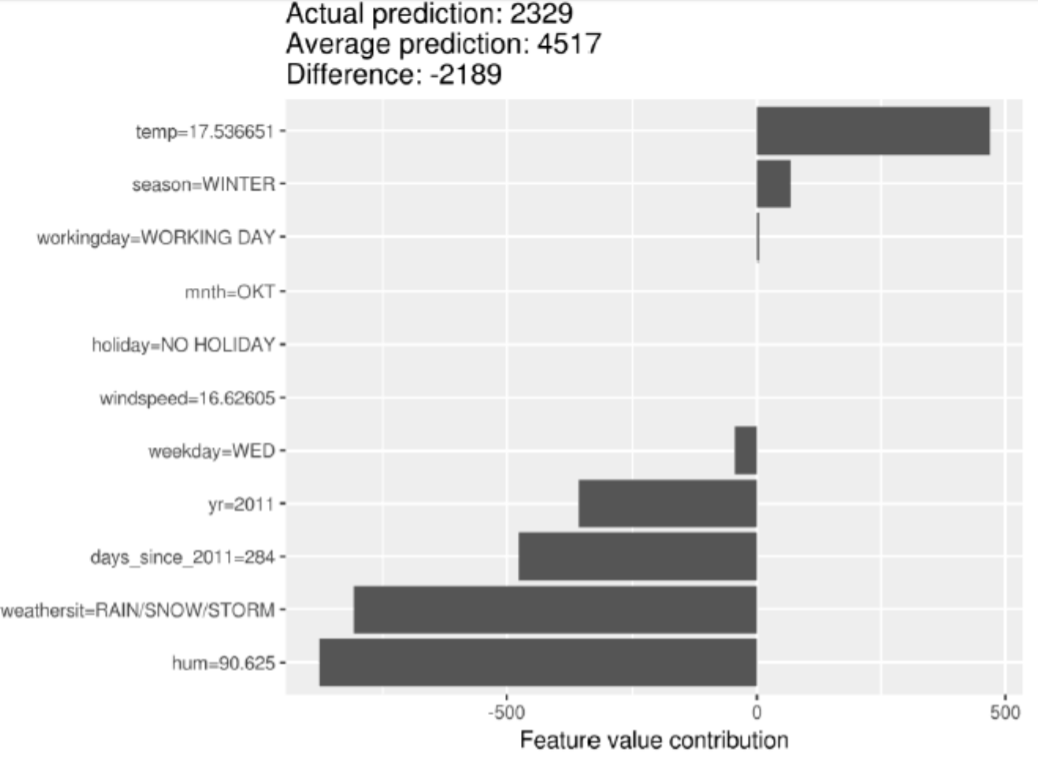
Shap Value는 실제값과 예측치의 차이를 설명하는 것이라 하였다. 위의 그래프를 보면, temp=17.536651과 season=WINTER은 명확하게 양의 영향력을 미치는 것을 확인할 수 있고, 아래 4개의 변수는 명확하게 음의 영향력을 미치는 것을 확인할 수 있다.
하지만, Shap Value는 특정 관측치의 실제 예측치와 평균 예측치의 평균적인 차이를 의미하는 것이지, 위의 그림에서 "temp를 높이면 target에 값이 500만큼 증가할 것이다."라는 해석은 주의해야한다. 즉, 예측을 하는데 효과적인 것이지, 인과관계를 투입하여 해석을 하면 안된다는 것이다.
Shap Value 예시
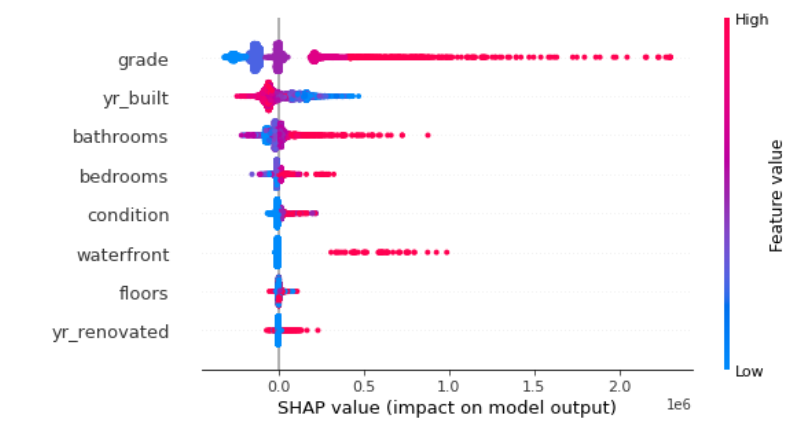
위의 결과는 집 가격을 target으로 하는 데이터의 shap value결과이다. 위를 해석하면, grade(등급)이 높으면 높을 수록 집 가격이 높아진다라는 관계를 발견할 수 있다.
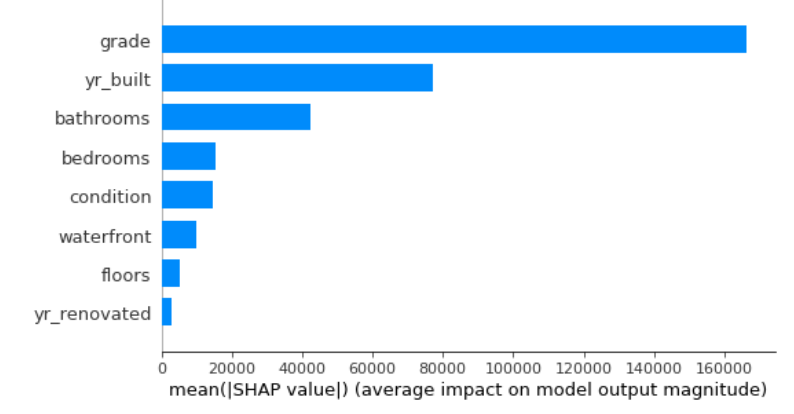
그리고 위의 그래프는 mean(|Shap Value|)로 grade의 영향력이 다른 변수들보다 평균적으로 크게 영향을 미치는 것을 확인할 수 있다.

위의 결과는 yr_built(지어진 년도)와 grade(등급)에 관한 shap value이다. 즉, 위를 보면 최신에 지어진 집일 수록 파란 부분이 적고 빨간 부분이 더 많이 분포하는 것을 확인할 수 있다. 이는 최신에 지어진 집일 수록 grade가 더 높은 경향이 있다고 판단된다.
이렇게 오늘은 주요변수를 추출하는 기준으로 feature importance와 shap value에 대해서 알아보았다. 아래 게시글을 통해서 Shap value를 Python으로 구현하는 실습을 남겨 놓겠다.
https://todayisbetterthanyesterday.tistory.com/57
[Python] 중요변수를 추출하기 위한 방법 - Shap Value 구현
*아래 학습은 Fastcampus의 "머신러닝 A-Z까지"라는 인터넷 강의에서 실습한 내용을 복습하며 학습과정을 공유하고자 복기한 내용입니다. 이 게시글은 오로지 파이썬을 통한 실습만을 진행한다. ��
todayisbetterthanyesterday.tistory.com